近日,北京大学心理与认知科学学院彭玉佳课题组在SCIENCE CHINA Technological Sciences上发表题为“Ability decomposition and difficulty quantification of visual tasks: Towards systematic evaluations of artificial general intelligence”的文章,系统探究了AI测试中的能力拆解和难度量化问题。
当前,多模态大模型飞速发展,我们正迈向通用人工智能(AGI)的时代。然而,一个核心问题尚未解决:我们如何科学、系统地评估一个AI模型是否真的具备了“通用智能”?传统的AI评测就像“单项考试”(如图像分类、文本情感分析),但AGI需要的是“综合能力大考”。现有的评测体系存在两大痛点:(1)“考什么”不清晰:一个复杂任务(如“根据指令从冰箱里拿香蕉”,图1)究竟考察了AI的哪些具体能力(如物体识别、空间推理、语言理解)?缺乏明确的分解。(2)“考题难度”不明确:哪些任务更难?难在何处?缺乏一个客观、量化的标准,导致评测结果难以解释,无法精准定位AI的短板。
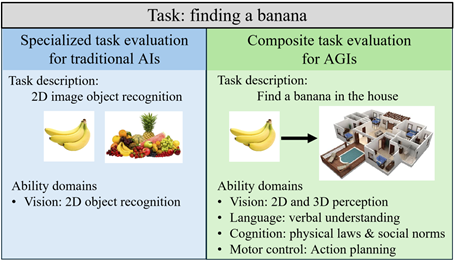
图1:像“找香蕉”这样的任务,既可以是很简单的图像识别(单一任务),也可以是涉及语言、推理和交互的复杂任务(复合任务)。
针对以上问题,北京大学心理学院彭玉佳研究员联合北京通用人工智能研究院(BIGAI)团队开发了一套可解释任务能力拆解及难度量化系统(Task ability decomposition and difficulty level quantification of vision, TADDL-V)。该系统如同一位“AI体检医生”,能够对任何视觉任务进行两大核心分析:第一,能力分解:利用大语言模型(GPT-4o),将复杂任务分解为所需的基本视觉能力。本研究定义了一个包含5项核心视觉能力的集合(V5),包括特征感知、物体感知、空间视觉、时序视觉和视觉推理。第二,难度量化:通过大规模人类问卷调查(收集了2415对任务难度比较结果),获取每个任务在人类眼中的相对难度。然后,团队创新性地提出了一个 “能力质量”模型,认为任务的总体难度由其所需的各种能力的“质量”叠加决定,并通过优化算法,为每项能力赋予了相应的“质量”值。
工作核心创新在于:
-
系统性:将AI测试的“能力分解”与“难度量化”在一个统一的、可解释的框架内结合。
-
可解释性:得出的“能力质量”值与人类直觉高度吻合(例如,“视觉推理”的质量远高于基础的“特征感知”),使得AI的能力评估结果清晰易懂。
-
可推广性:该方法论不仅限于视觉,未来可扩展至语言、记忆等多模态能力。
实验结果
1. 系统评估结果符合人类直觉
通过优化计算出的五项视觉能力的“质量”值,呈现出清晰的梯度:基础感知能力(如特征感知)质量较低,而高级认知能力(如视觉推理)质量最高。这与我们对能力难度的认知完全一致,证明了TADDL-V系统的合理性(图2)。
2. 精准诊断现有评测体系的“偏科”现象
研究团队利用TADDL-V分析了现有的两个著名具身AI基准(BEHAVIOR-100和BEHAVIOR-1K),以及本工作构建的新基准AGI-V70(包含70个复合视觉任务)(图2)。分析发现,BEHAVIOR系列任务所考察的能力高度集中于“物体感知”和“空间视觉”,而“特征感知”和高级的“视觉推理”能力则很少被考察,存在明显的“偏科”。同时,其任务难度分布范围较窄,可能无法有效区分不同水平的AI智能体。相比之下,AGI-V70在能力覆盖广度和难度分布范围上都更优,能为AI提供更全面的“体检”。最后,在与人工神经网络等基线模型的对比中,TADDL-V表现出色。更重要的是,在针对未参与训练的新任务的测试中,TADDL-V的难度预测与人类判断的吻合度超过80%,证明了其强大的泛化能力。
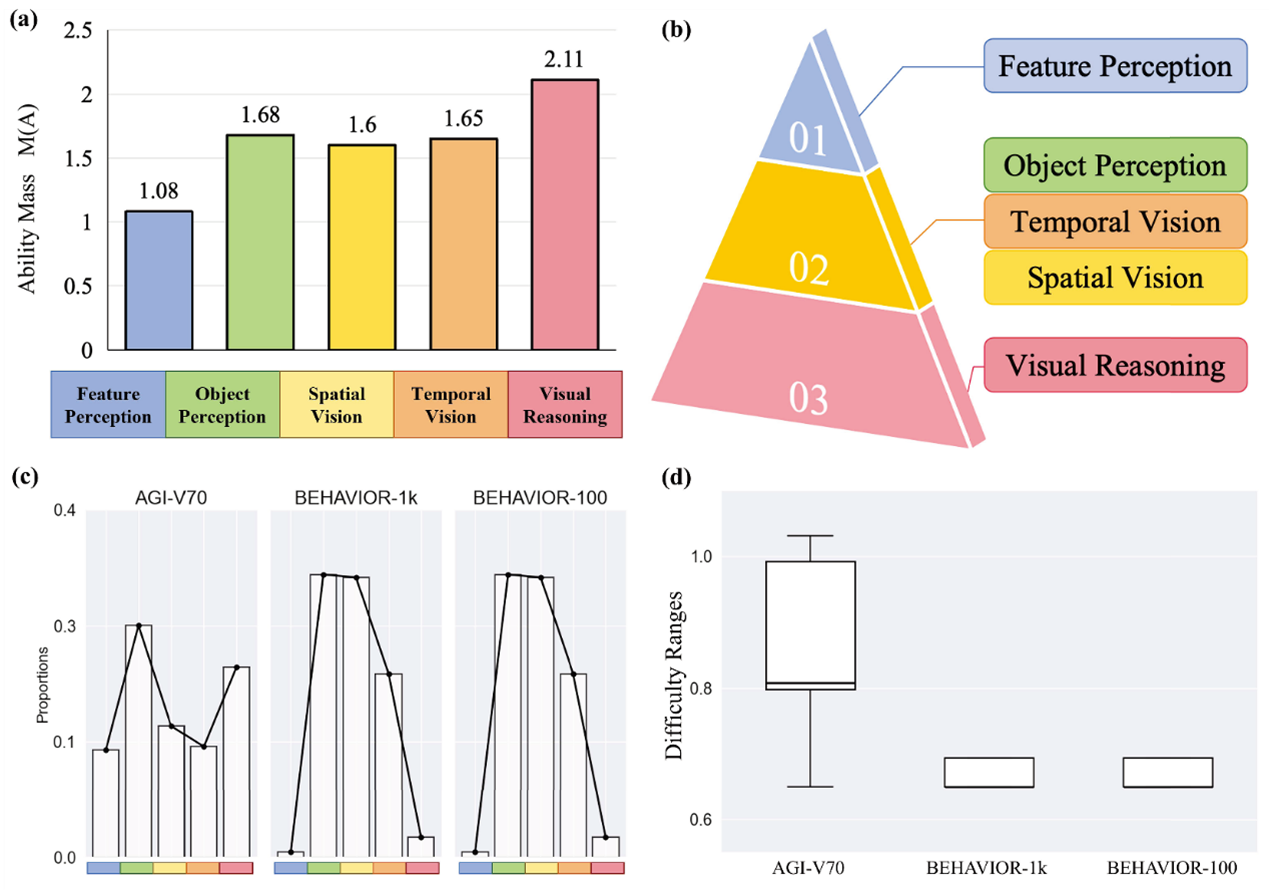
图2:五大能力集的“能力质量”和语义关系对比及数据集的能力分布对比。
总结与展望
本研究提出的TADDL-V系统,为系统化、可解释地评估通用人工智能迈出了关键一步。它不仅是一个实用的评估工具,更能像“雷达”一样,帮助我们发现现有AI模型的能力边界和评测基准的盲区,从而指引AGI研究向着更全面、更深入的方向发展。未来,团队计划将这一框架扩展到更多模态(如语言、听觉),以期最终构建一套完整的AGI综合测评体系。
本文第一作者为北京大学元培学院崔绍洋,通讯作者为彭玉佳研究员。研究得到了跨媒体通用人工智能全国重点实验室、科技部重大项目(2022ZD0114900)、国家自然科学基金(32471151, 32200854)和中国科协青年人才托举项目 (No. 2021QNRC00) 的支持。
全文链接:
https://www.sciengine.com/SCTS/doi/10.1007/s11431-025-3090-5
引用:
CUI Shaoyang, HE Xinyi, HAN Jiaheng, ZHANG Zhenliang, PENG Yujia. Ability decomposition and difficulty quantification of visual tasks: Towards systematic evaluations of artificial general intelligence. SCIENCE CHINA Technological Sciences, 2025-10-27.
2025-10-27